Paper Accepted to CBMS 2024!
Our paper entitled “Exploring Alternative Data Augmentation Methods in Dysarthric Automatic Speech Recognition” was just accepted for publication in the IEEE International Symposium on Computer-Based Medical Systems.
Dysarthria encompasses various speech disorders resulting from changes in the control of muscles involved in phoneme production. These alterations stem from central or peripheral nervous system lesions, causing issues in oral communication due to paralysis, weakness, or lack of muscular coordination in word articulation. The causes of dysarthria may vary depending on the region of the affected nervous system and can be classified into different types, including hypokinetic dysarthria, causing hoarseness and voice tremors, and hyperkinetic dysarthria, leading to problems in vowel pronunciation and breathiness in speech.
Given the intrinsic characteristics of motor speech impairments, Automatic Speech Recognition (ASR) systems do not perform well when used by individuals with difficulties in oral language articulation, such as dysarthric patients. Many researchers from various fields have made efforts to find an efficient solution to communication problems faced by these patients.
However, these efforts encounter challenges due to the limited availability of robust dysarthric voice databases. To address this limitation, researchers have resorted to techniques such as speech synthesis and noise addition to audio recordings. Such solutions pose challenges like time demands for training a deep learning system for speech synthesis and adding anomalies to original audio, which would then need to undergo the process of converting audio recordings into spectral images.
Therefore, means of augmenting data during the loading and structuring process of datasets in the course of training neural networks can become a viable alternative to those adopted in other reported research.
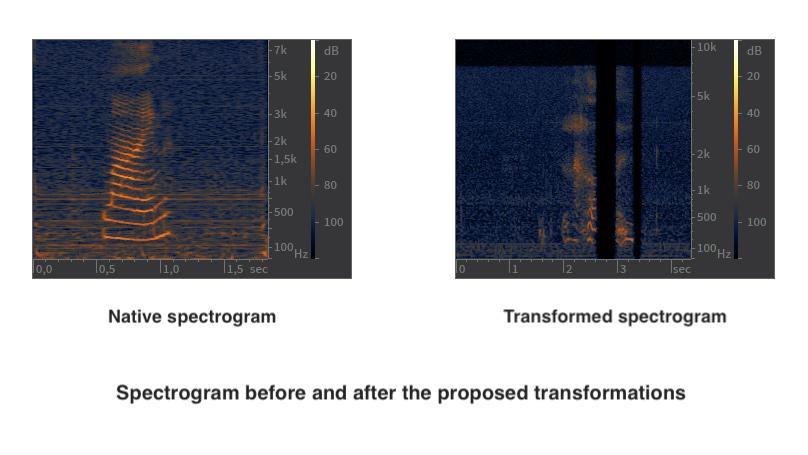
Motivated by such observations, we explore the effectiveness of data augumentation methods in the context of dysarthric speech recognition systems. Specifically, we focus on evaluating two distinct techniques: the first one, using noise addition and time dilation; and the second one, named Spectral Occlusion (SO), which is a novel approach that we propose in this paper. This analysis focuses on observing the potential of these techniques to preserve or enhance the accuracy of Dysarthric Automatic Speech Recognition (DASR) systems.
Do you want to know more about augmenting data for training intelligent systems to decipher dysarthric speech? Check our paper!
Jurandy Almeida
Professor of Computer Science
My research interests are mainly in the areas of computer vision, deep learning, image processing, information retrieval, machine learning, and pattern recognition.