Paper Accepted to IWSSIP 2024!
Our paper entitled “Action Recognition in the Compressed Domain: A Neural Search Approach” was just accepted for publication in the International Conference on Systems, Signals and Image Processing.
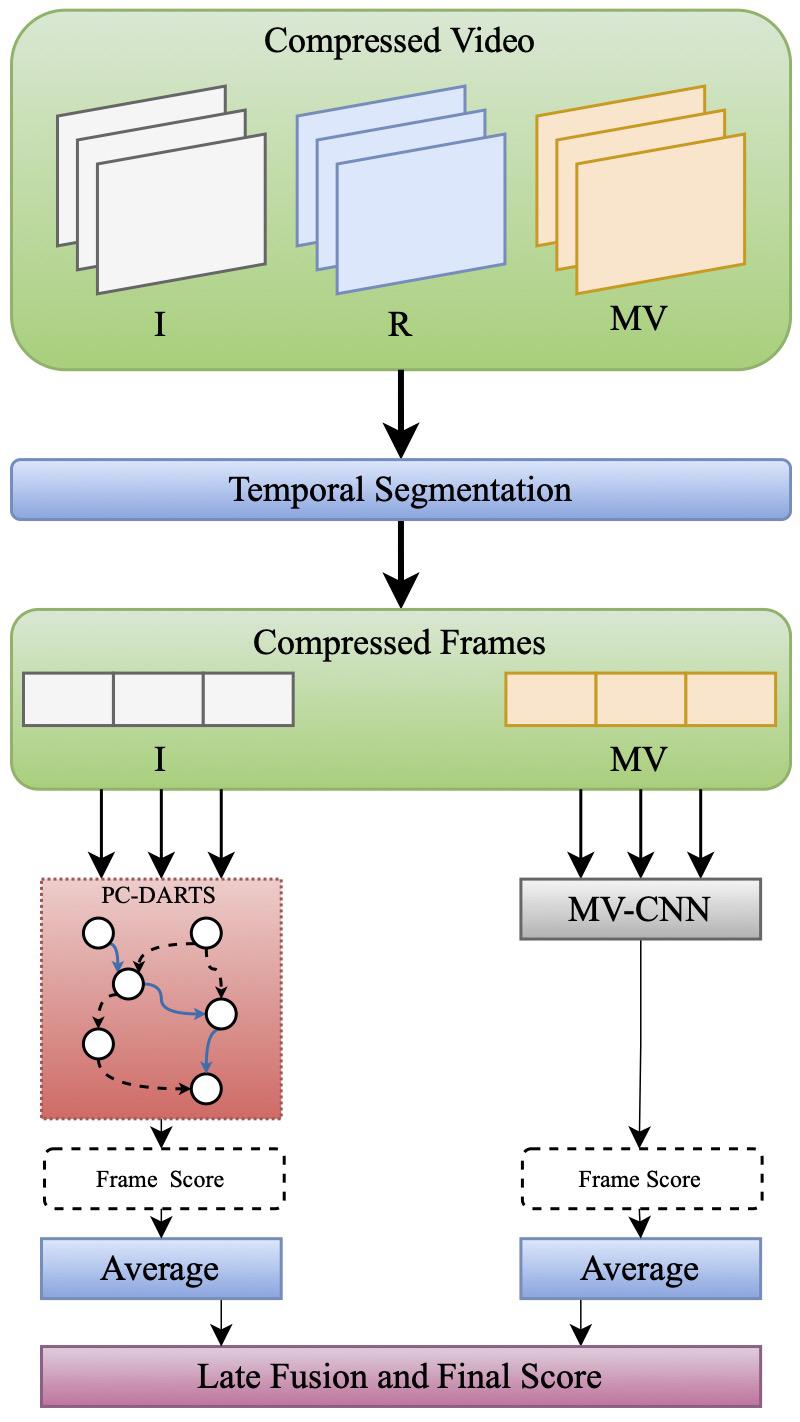
Many applications today rely on deep learning models. Some of these advances came from an interest in developing deeper architectures with many parameters. Such an approach leads to an increase in model parameters, considerably demanding computational costs, and the chance of overfitting (Santos et al., 2023). Models dealing with temporal structures of videos are even more complex due to this temporal dependency. For training, a large amount of video requires decoding (i.e., obtaining its RGB representation) since most of its data relies on compressed file formats. In addition, most existing models for such computer vision tasks have been designed specifically for RGB frame sequences.
In many cases, it is common to use compressed formats to store images (e.g., JPEG, PNG, GIF) and videos (e.g., MPEG- 4, H.264), whether for transmission speed or storage. Notably, the most common compression formats for images and videos, JPEG and MPEG-4, respectively, have the same coding strategy based on block transformations in the frequency domain, with little loss in quality. As a result, several studies have focused on developing models that can use data in the compressed domain to speed up training and inference using fewer computational resources.
In the MPEG-4 compressed video format, information is encoded in groups of pictures containing intra-coded, predicted, and bidirectionally predicted frames (I, P, and B frames, respectively). In short, the encoded video contains static frame information, motion vectors in blocks, and residuals of these vectors about the static frames.
Since a current paradigm is feature extraction using deep learning models, researchers can focus on designing and building networks. Thus, choosing a video architecture is not an easy task. It can involve manual construction by experts, making it difficult for beginners to modify existing networks to suit their needs (Ren et al., 2022). Neural Architecture Search (NAS) methods can automate the process of building networks, with equivalent or better results than manually engineered networks, by learning a representation that best suits a task with minimal human intervention. The idea of exploiting neural networks that are automatically built is not new (Stanley and Miikkulainen, 2022), but due to advances in search efficiency and training, the methods have become computationally viable.
In this paper, we present a method for automatically constructing networks based on an efficient differentiable search and a two-stream network framework for joining the frequency domain and motion vectors to perform action recognition in the compressed domain. This combination makes the method relatively computationally efficient and less complex than existing architectures.
Do you want to know more about finding the most effective neural network architectures for the compressed domain? Check our paper!
Jurandy Almeida
Professor of Computer Science
My research interests are mainly in the areas of computer vision, deep learning, image processing, information retrieval, machine learning, and pattern recognition.