Paper Accepted to WACV 2025!
Our paper entitled “Transferable-guided Attention Is All You Need for Video Domain Adaptation” was just accepted for publication in the IEEE/CVF Winter Conference on Applications of Computer Vision.
With the popularization of social media platforms focused on user-generated content, a huge volume of data is generated. The cataloging and searching of this content is necessary, however, manually analyzing this immense amount of content is practically impossible, making video analysis tasks crucial. Among the several video analysis tasks, action recognition is one of the most popular and challenging ones since there is a significant number of variations in the manner the action can be carried out and captured, for example, speed, duration, camera and actor movement, occlusion, etc (Costa et al., 2022).
Various deep learning methods for action recognition are available in the literature. These approaches can be classified based on how they handle the temporal dimension. Some use 3D models to capture spatial and temporal features, while others treat spatial and temporal data separately or employ Recurrent Neural Networks (RNNs) to model the temporal dynamics (Kong and Fu, 2022). Despite all the advances, human costs are high, as many video annotations are needed to yield good results. Obtaining and annotating a desirable amount of data is difficult for many application domains, requiring significant human effort and specific knowledge (Wang et al., 2017).
Unsupervised Domain Adaptation (UDA) can be used to reduce the cost of manually annotating data. In these strategies, the model is trained with labeled data from a source domain and unlabeled data from a target domain to perform well on the target domain’s test set. Since there is a domain change between source and target, UDA methods must deal with the distribution mismatch generated by the domain gap, since the domains might have different backgrounds, illumination, camera position, etc (Chen et al., 2022). Several methods have been proposed to address this issue, however, most of these works are for image UDA, and video UDA is considerably less explored and significantly more challenging, as it requires handling the temporal aspects of the data (Costa et al., 2022).
Only a few recent works tackle video UDA for action recognition using deep learning with strategies like contrastive learning, cross-domain attention mechanisms, self-supervised learning, and multi-modalities of data. An amount even lower of works explore Vision Transformer (ViT) architectures. Although existing methods have improved the performance of UDA for action recognition, some limitations remains unexplored. First, they focus on aligning frames with a larger spatial and temporal domain gap across an entire video, but we hypothesize that frames with a smaller domain gap have a more meaningful action representation and can improve the adaptability. Also, none of them investigate how to improve ViT for video UDA.
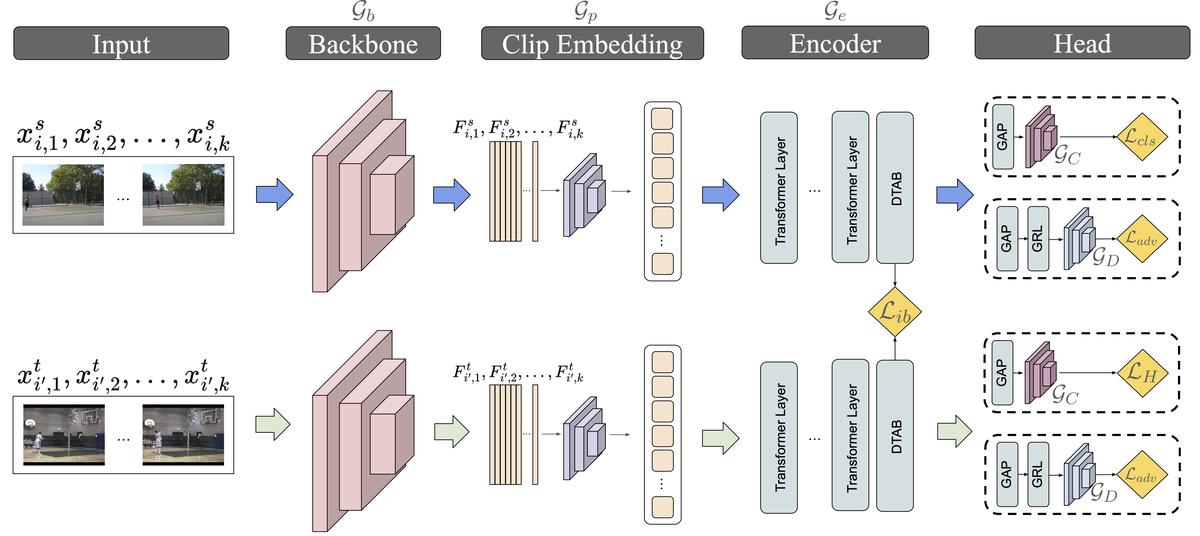
To address the mentioned issues, we propose a novel method for video UDA, called Transferable-guided Attention (TransferAttn). Architecturally, TransferAttn utilizes a ViT as a feature encoder for domain adaptation. The encoder consists of four transformer blocks, with the last one incorporating our novel attention mechanism, named Domain Transferable-guided Attention Block (DTAB), which compels ViT to encourage spatial-temporal transferability among video frames from different domains.
Do you want to know more about improving the transferability of a ViT for unsupervised domain adaptation? Check our paper!
Jurandy Almeida
Professor of Computer Science
My research interests are mainly in the areas of computer vision, deep learning, image processing, information retrieval, machine learning, and pattern recognition.