New Journal Paper Out!
Our paper entitled “Low-Budget Label Query through Domain Alignment Enforcement” was just published in the Computer Vision and Image Understanding journal.
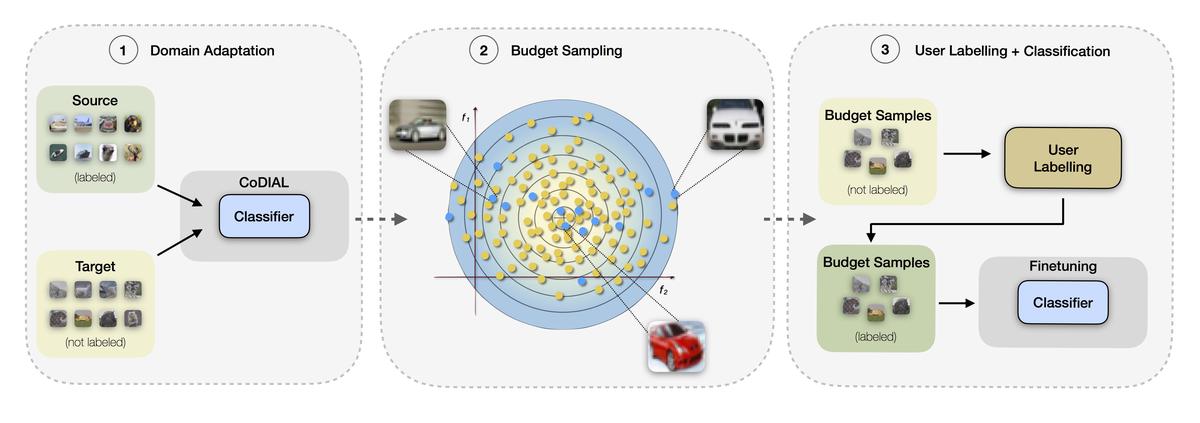
In this work, we tackle the problem of having a very limited budget for data labeling by defining a methodology that deterministically identifies a convenient small subset of data to be manually labelled thus becoming usable for practical applications. To the best of our knowledge, this is an entirely novel problem that is relevant for a wide range of tasks, in particular for industrial applications where a reasonable amount of data is available but budget for labeling is limited.
Deciding which samples have to be prioritized for labeling in a new unseen dataset is a non-trivial task. In this work, we dig into this direction to review methods that are able to automatically select a pool of samples from an unlabelled dataset that once manually labeled, they maximize the classification performance in such dataset. We refer to this problem as low-budget label query.
While a first approach to this problem might be the use of a pre-trained model with known selection metrics (Lewis and Gale, 1994; Beluch et al., 2018), we argue selection metrics to be unreliable in real-world applications where predictions are prone to domain shift, i.e., training (source) and test (target) data distributions differ. The proposed approach is divided into three main phases: Domain Adaptation, Budget Sampling, and User Labelling.
In the first phase, we adapt the source trained model through UDA to align the feature distributions of the source (labeled) and target (unlabeled) datasets. This domain agnostic model is then used as reference to compute the classification uncertainty of each sample in the target dataset. This phase is critical as we need a model capable of producing a good metrics for sample reliability. Such reliability, however, is not a warranty of good decision considering that neural networks tend to predict with over-confidence even when they are suggesting a wrong prediction (Guo et al., 2017; Zou et al., 2019). To this end, we took inspiration from AutoDIAL (Carlucci et al., 2017), where the distributions of source and target are aligned towards the separate computation of the batch normalization layers' statistics and the model is trained using two simple losses, one supervised and one unsupervised for the source and the target, respectively. In the first phase, we improved AutoDIAL by replacing the unsupervised entropy loss with a cost function that maximizes the consistency between pristine target images and their randomly perturbed versions. This modification improves the accuracy of the UDA on most datasets we considered. We named this method as Co-DIAL (Consistency DIAL).
In the second phase, we investigate a set of criteria to sample a fixed set of samples (i.e., low budget query) that are convenient to be labeled with the final goal to maximizing the overall classification accuracy of the neural network. These pool of samples shall be selected using no supervision and therefore we focused on a set of methods that do not require ground truth to be utilized. To this aim, we conduct an in-depth experimental study with commonly used selection metrics, i.e., entropy and consistency, and with multiple sampling strategies. In the final phase, the selected samples are human-annotated and used to train a classifier obtaining a model that is able to perform well on the target dataset.
Do you want to know more about deciding which samples have to be prioritized for labeling in a new unseen dataset? Check our paper!
Jurandy Almeida
Professor of Computer Science
My research interests are mainly in the areas of computer vision, deep learning, image processing, information retrieval, machine learning, and pattern recognition.