New Journal Paper Out!
Our paper entitled “Budget-Aware Pruning: Handling Multiple Domains with Less Parameters” was just published in the Pattern Recognition journal.
Deep learning has brought astonishing advances to computer vision, being used in several application domains. However, to increase the performance, increasingly deeper architectures have been used (Liu et al., 2021), leading to models with a high computational cost. Also, for each new domain (or task) addressed, a new model is usually needed (Berriel et al., 2019). The significant amount of model parameters to be stored and the high GPU processing power required for using such models can prevent their deployment in computationally limited devices, like mobile phones and embedded devices (Du et al., 2021). Therefore, specialized optimizations at both software and hardware levels are imperative for developing efficient and effective deep learning-based solutions (Marchisio et al., 2019).
For this motive, there has been a growing interest in learning multiple complex problems jointly, such as Multi-Task Learning (MTL) and Multi-Domain Learning (MDL) methods. These approaches are based on the observation that, although the tasks and domains can be very different, it is still possible that they share a significant amount of low and mid-level visual patterns (Rebuffi et al., 2017). MTL extracts diverse information from a given sample, tackling multiple tasks, like object detection and segmentation. While MDL aims to perform well in different visual domains, like medical images, images from autonomous vehicles, and handwritten text. Both MTL and MDL goal is to learn a single compact model that performs well in several tasks/domains while sharing the majority of the parameters among them with only a few specific ones. This reduces the cost of having to store and learn a whole new model for each new task/domain.
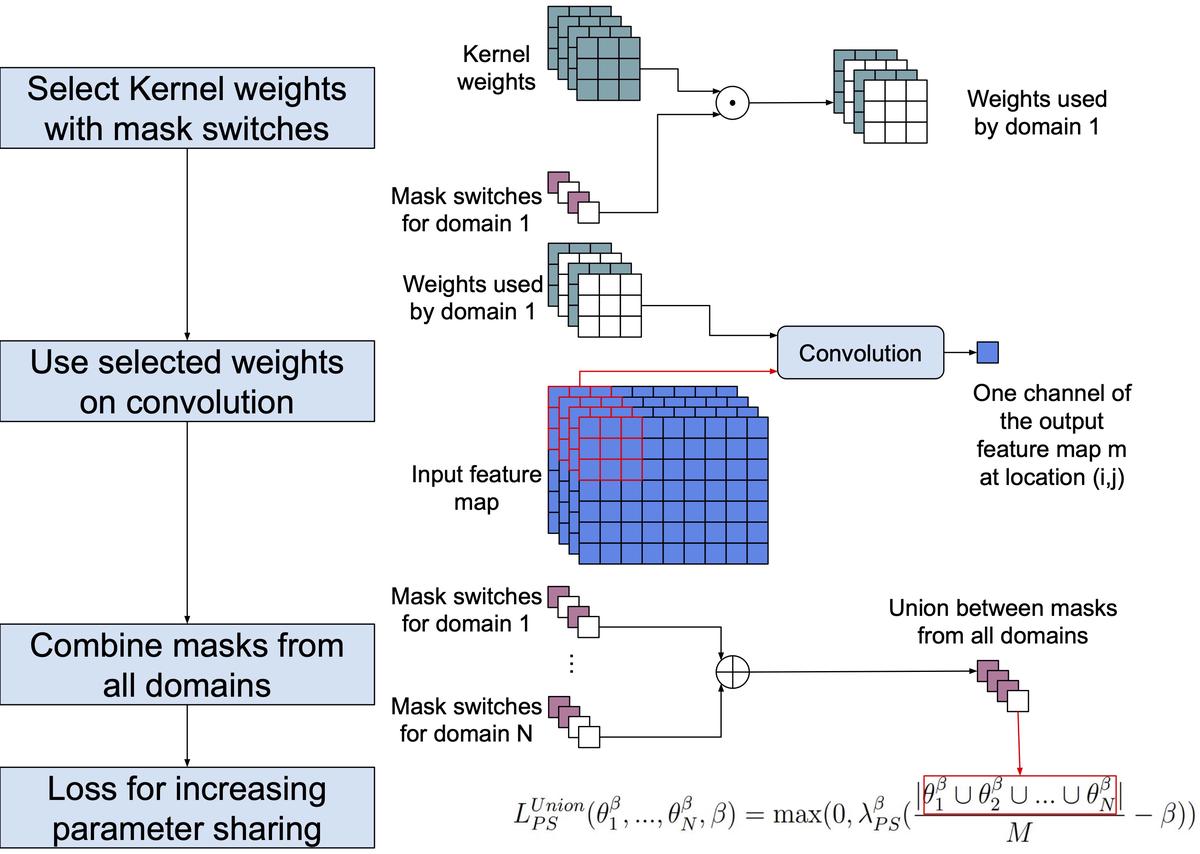
Berriel et al., 2019 point out that one limitation of those methods is that, when handling multiple domains, their computational complexity is at best equal to the backbone model for a single domain. Therefore, they are not capable of adapting their amount of parameters to custom hardware constraints or user-defined budgets. To address this issue, they proposed the modules named Budget-Aware Adapters (BA$^2$) that were designed to be added to a pre-trained model to allow them to handle new domains and to limit the network complexity according to a user-defined budget. They act as switches, selecting the convolutional channels that will be used in each domain.
However, as mentioned by Berriel et al., 2019, although this approach reduces the number of parameters required for each domain, the entire model still is required at test time if it aims to handle all the domains. The main reason is that they share few parameters among the domains, which forces loading all potentially needed parameters for all the domains of interest.
Our work builds upon the BA$^2$ (Berriel et al., 2019) by encouraging multiple domains to share convolutional filters, enabling us to prune weights not used by any of the domains at test time. Therefore, it is possible to create a single model with lower computational complexity and fewer parameters than the baseline model for a single domain. Such a model can better fit into a user’s budget that has access to limited computational resources.
Do you want to know more about pruning models for multiple domains according to a user budget? Check our paper!
Jurandy Almeida
Professor of Computer Science
My research interests are mainly in the areas of computer vision, deep learning, image processing, information retrieval, machine learning, and pattern recognition.