New Journal Paper Out!
Our paper entitled “Beyond the Known: Enhancing Open Set Domain Adaptation with Unknown Exploration” was just published in the Pattern Recognition Letters.
Deep Learning (DL) methods have been obtaining astonishing results in several research areas recently, particularly, Convolutional Neural Networks (CNNs) are widely used in computer vision problems (Geng et al., 2021). However, these methods usually operate under unrealistic ideal conditions, where the dataset is fully labeled and belongs to a Closed Set (CS) of categories (Geng et al., 2021). In real-world scenarios, these conditions are not always feasible, and labeling data is often time-consuming, expensive, or even impossible. As a result, DL methods designed for working with supervised datasets often struggle when faced with unlabeled or partially labeled datasets (Bucci et al., 2020, Saltori et al., 2022).
Two main problems arise in uncontrollable environments: decreased levels of supervision and lack of control over incoming data. To deal with the decreased level of supervision, a fully annotated dataset (i.e., source domain) similar to the unlabeled target dataset (i.e., target domain) is used to train the model. However, since the data may have different distributions, this may lead to the domain-shift problem (Silva et al., 2021). To deal with the lack of control over the incoming data, the model must be capable of handling examples from possible unknown categories during inference. This is necessary due to the category-shift that may occur between our training and test data as we do not know all data beforehand (Chen et al., 2022). The domain-shift and category-shift problems have their own research areas dedicated to mitigating them individually, the Unsupervised Domain Adaptation (UDA) and Open Set (OS) recognition, respectively. Recently, the more challenging scenario where both domain-shift and category-shift problems occur simultaneously was introduced by Busto and Gall, 2017, being named Open Set Domain Adaptation (OSDA).
Usually in OSDA methods, unknown samples in the target domain are rejected, while known samples from the target domain are aligned with the source domain (Loghmani et al., 2020). To achieve this, sets of high-confidence known and unknown samples from the target domain are selected. The positive samples from the known set are aligned with the source domain to mitigate the domain shift (Bucci et al., 2020, Rakshit et al., 2020, Bucci et al., 2022), while the negative samples from the unknown set are usually unexplored during training, being only assigned to an additional logit of the classifier that represents the unknown category and is learned with supervision together with the other classes (Liu et al., 2022). Recent works (Liu et al., 2022, Baktashmotlagh et al., 2022) leverage negative samples from the unknown set to improve their OSDA approaches, since this data is highly informative, having complicated semantics and possible correlation to known classes that can hinder oversimplified approaches (Liu et al., 2022).
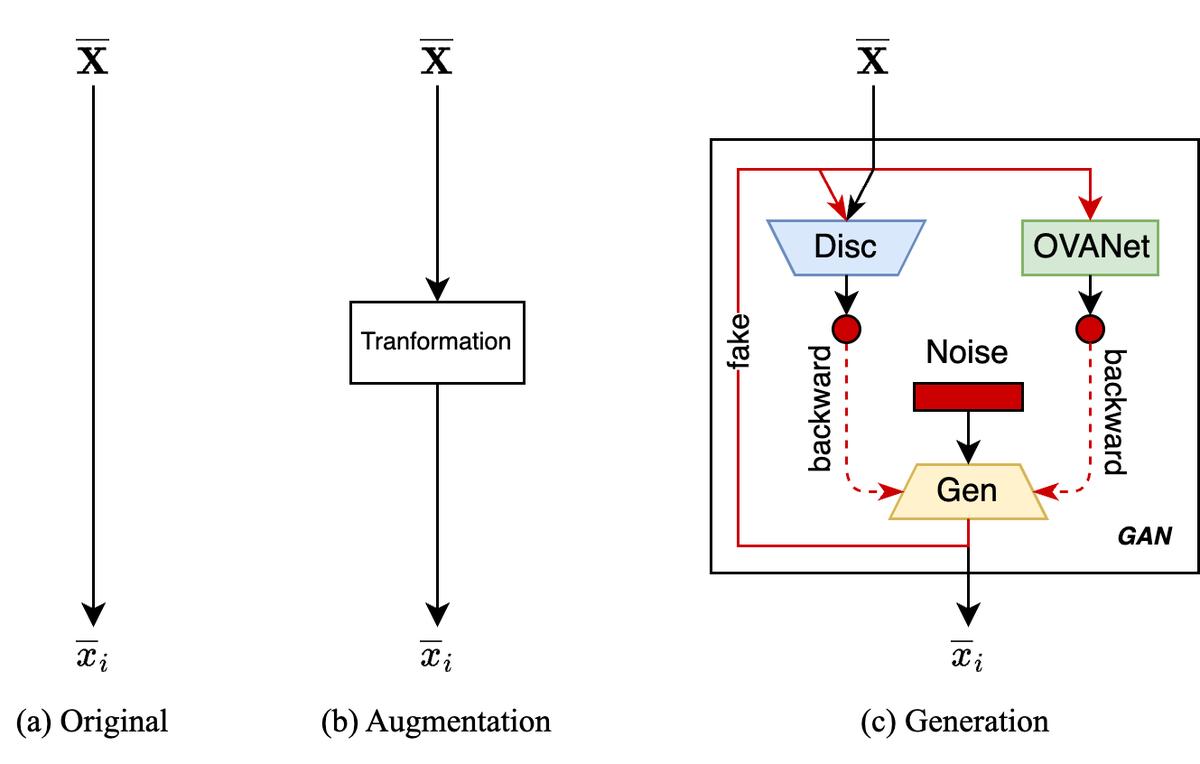
In light of recent works on closed-set relationships with OS (Vaze et al., 2022) and unknown exploitation (Liu et al., 2022, Baktashmotlagh et al., 2022), we hypothesize that the classification performance can be further improved by using unknown samples from the target domain to tighten the boundaries of the closed-set classifier. To investigate this hypothesis for the OSDA setting, we propose a three-way extension to OVANet (Saito and Saenko, 2021), an UNiversal Domain Adaptation (UNDA) method. In our method, high-confidence negatives are extracted from the target domain based on a higher confidence threshold (Rakshit et al., 2020) and, then (1) we evaluate the use of a new constraint for the classification of known samples based on the direct use of pure negatives (original approach), (2) we apply data augmentation to these negatives before using them in the aforementioned classification constraint (augmentation approach), and (3) we train a Generative Adversarial Network (GAN) model with these negatives to generate negative/adversarial examples, teaching OVANet to reject these synthetic instances that are posed as positives (generation approach). We also conduct ablation studies over the generation approach in order to improve the GAN discriminator and training procedure (generation++ approach).
Do you want to know more about using unknown samples to tighten the classification boundaries? Check our paper!
Jurandy Almeida
Professor of Computer Science
My research interests are mainly in the areas of computer vision, deep learning, image processing, information retrieval, machine learning, and pattern recognition.