Exploring Alternative Data Augmentation Methods in Dysarthric Automatic Speech Recognition
Abstract
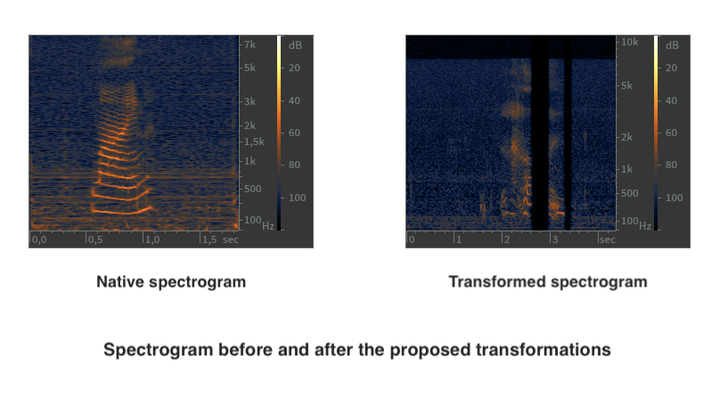
Patients with dysarthria face challenges in verbal communication, which affects their interaction with speech-activated devices. Intelligent systems that can interpret dysarthric speech could significantly enhance their quality of life. Neural Networks (NN) and Convolutional Neural Networks (CNN) have been used for sparse word classification in dysarthric speech, achieving an average accuracy of 64.1%. Spatial Convolutional Neural Networks (SCNN) and Multi-Head Attention Transformers (MHAT) have improved this accuracy by 20%. However, these methods have been tested on limited databases and yield specific results, making their application in more natural speech environments challenging. To address the lack of dysarthric speech data, some researchers have used speech synthesis techniques, but they require extensive training and careful database structuring. To alleviate this problem, we explore data augmentation methods based on the spectral characteristics of dysarthric speech, which focus on transforming spectrographic images extracted from available audio files. Two such methods were implemented and achieved results similar to complex state-of-the-art solutions.
Ricardo Alexandre Gracelli
MSc Student
My research interests include deep learning and machine learning.
Jurandy Almeida
Professor of Computer Science
My research interests are mainly in the areas of computer vision, deep learning, image processing, information retrieval, machine learning, and pattern recognition.