Neural Architecture Search for Enhancing Action Video Recognition in Compressed Domains
Abstract
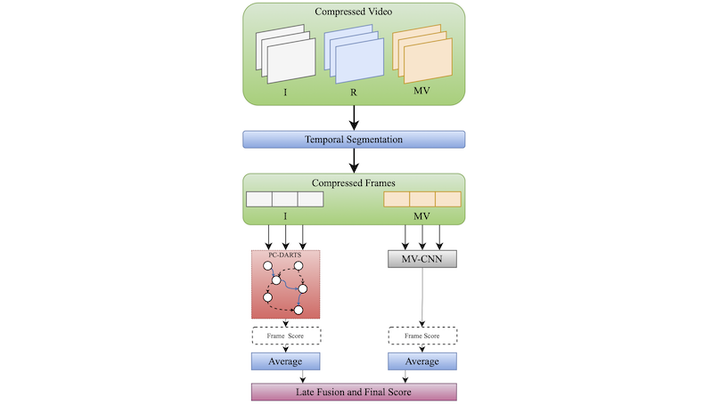
Video classification models have become one of the most widely used topics in the computer vision field, encompassing many tasks such as medical, security, industrial, and other applications. Although deep learning models have achieved great results in the video domain, such models are built to operate in the domain of RGB frame sequences. In such models, a prior step is required for decoding video data since the vast majority relies on compressed formats. Nevertheless, large amounts of computational resources are required for decoding, especially in real-time. Researchers have already tackled the task of building networks that work in the compressed domain with promising results but with architectures still very close to those used for the RGB domain. We propose an approach that employs Neural Architecture Search to explore and find the most effective architectures for the compressed domain. Our approach was tested on UCF101 and HMDB51 datasets, obtaining a computationally less complex architecture than similar methods.
Jurandy Almeida
Professor of Computer Science
My research interests are mainly in the areas of computer vision, deep learning, image processing, information retrieval, machine learning, and pattern recognition.