Transferable-guided Attention Is All You Need for Video Domain Adaptation
Abstract
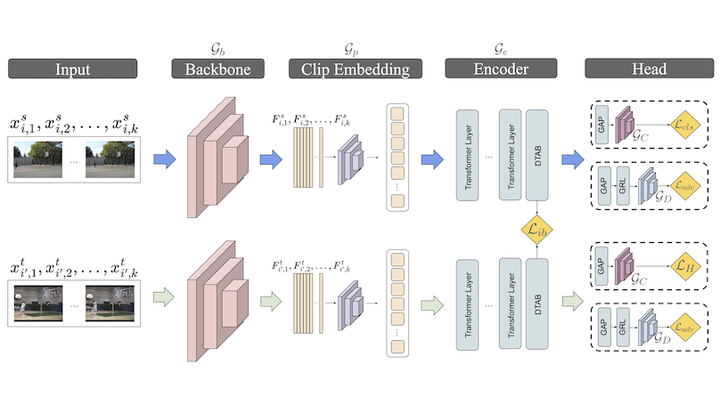
Unsupervised domain adaptation (UDA) in videos is a challenging task that remains not well explored compared to image-based UDA techniques. Although vision transformers (ViT) achieve state-of-the-art performance in many computer vision tasks, their use in video UDA has been little explored. Our key idea is to use transformer layers as a feature encoder and incorporate spatial and temporal transferability relationships into the attention mechanism. A Transferable-guided Attention (TransferAttn) framework is then developed to exploit the capacity of the transformer to adapt cross-domain knowledge across different backbones. To improve the transferability of ViT, we introduce a novel and effective module, named Domain Transferable-guided Attention Block (DTAB). DTAB compels ViT to focus on the spatio-temporal transferability relationship among video frames by changing the self-attention mechanism to a transferability attention mechanism. Extensive experiments were conducted on UCF-HMDB, Kinetics-Gameplay, and Kinetics-NEC Drone datasets, with different backbones, like ResNet101, I3D, and STAM, to verify the effectiveness of TransferAttn compared with state-of-the-art approaches. Also, we demonstrate that DTAB yields performance gains when applied to other state-of-the-art transformer-based UDA methods from both video and image domains. Our code is available at https://github.com/Andre-Sacilotti/transferattn-project-code.
Samuel Felipe dos Santos
Post-Doc
My research interests include computer vision, deep learning, information retrieval, and machine learning.
Jurandy Almeida
Professor of Computer Science
My research interests are mainly in the areas of computer vision, deep learning, image processing, information retrieval, machine learning, and pattern recognition.