Abstract
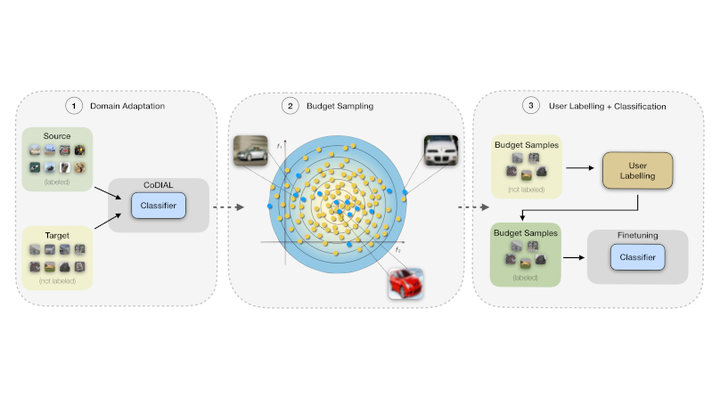
Deep learning revolution happened thanks to the availability of a massive amount of labeled data which contributed to the development of models with extraordinary inference capabilities. Despite the public availability of large-scale datasets, to address specific requirements it is often necessary to generate a new set of labeled data whose production is often costly and require specific know-how to be fulfilled. In this work, we propose the new problem of low-budget label query, which aims at maximizing the classification performance by selecting a convenient and small set of samples (i.e., low budget) to be manually labeled from an arbitrary big set of unlabeled data. While a first solution might be the use of pre-trained models with standard selection metrics, i.e., confidence and entropy, we argue that domain shift affects their reliability. We deem that Unsupervised Domain Adaptation (UDA) can be used to reduce domain shift, making selection metrics more reliable and less noisy. Therefore, we first improve an UDA method to better align source and target domains using consistency constraints, reaching comparable performance with the state of-the-art on several UDA tasks. After adaptation, we conduct an extensive experimental study with commonly used confidence metrics and sampling strategies to achieve low-budget label query on a large variety of publicly available datasets and under different setups.
Jurandy Almeida
Professor of Computer Science
My research interests are mainly in the areas of computer vision, deep learning, image processing, information retrieval, machine learning, and pattern recognition.