Abstract
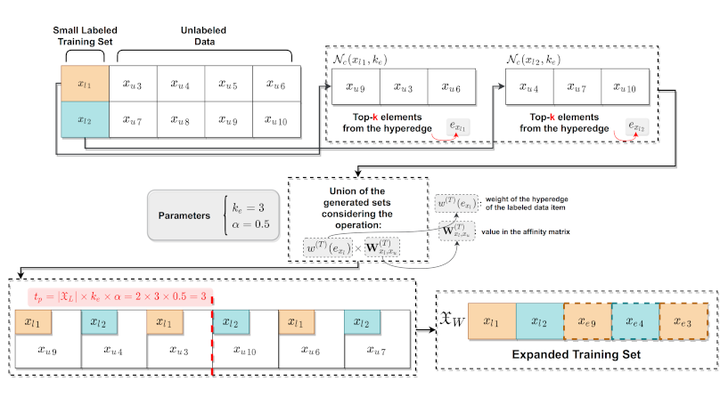
Significant challenges still remain despite the impressive recent advances in machine learning techniques, particularly in multimedia data understanding. One of the main challenges in real-world scenarios is the nature and relation between training and test datasets. Very often, only small sets of coarse-grained labeled data are available to train models, which are expected to be applied on large datasets and fine-grained tasks. Weakly supervised learning approaches handle such constraints by maximizing useful training information in labeled and unlabeled data. In this research direction, we propose a weakly supervised approach that analyzes the dataset manifold to expand the available labeled set. A hypergraph manifold ranking algorithm is exploited to represent the contextual similarity information encoded in the unlabeled data and identify strong similarity relations, which are taken as a path to label expansion. The expanded labeled set is subsequently exploited for a more comprehensive and accurate training process. The proposed model was evaluated jointly with supervised and semi-supervised classifiers, including Graph Convolutional Networks. The experimental results on image and video datasets demonstrate significant gains and accurate results for different classifiers in diverse scenarios.
Samuel Felipe dos Santos
Post-Doc
My research interests include computer vision, deep learning, information retrieval, and machine learning.
Jurandy Almeida
Professor of Computer Science
My research interests are mainly in the areas of computer vision, deep learning, image processing, information retrieval, machine learning, and pattern recognition.