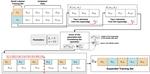
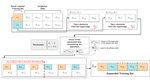
In this work, we propose a weakly supervised approach for classification scenarios where only small labeled sets are available. It exploits hypergraph structures based on ranking information to identify and select reliable similarity relations between pairs of labeled-unlabeled data.