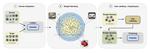
In this work, we propose the new problem of low-budget label query, which aims at maximizing the classification performance by selecting a convenient and small set of samples (i.e., low budget) to be manually labeled from an arbitrary big set of unlabeled data.